SpamBayes 日本語化
spambayes japanese localize
 SpamBayes
はベイズ理論を利用したスパムフィルタです。
Python で書かれています。
SpamBayes
はベイズ理論を利用したスパムフィルタです。
Python で書かれています。
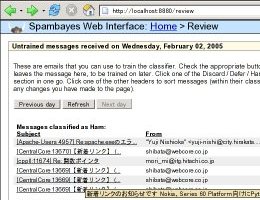
軽くてフィルタ効率が良いと評判のプログラムなのですが、日本語メールに対応していません。
スパムメールを振り分ける時に Subject が文字化けしてしまい困ります。
統計に人間の意志を加味するところが肝ですから残念。
ちょっとだけ修正してみました。
とりあえず Subject の文字化け対処と、
マウスカーソルを上に持って行ったときに出るサマリ表示はうまくいきました。
パッチは (ProxyUI, PyMeldLite)
の二つです。
これは試験版 (無保証、無責任) なので、利用なさりたい方は覚悟の上でどうぞ。
課題はもう一つあって、日本語トークンの分離ができていません。
日本語メールの場合フィルタ効率が落ちるという話もあります。
また中文やハングルの場合どうなるのか解かりません。
まあ、Subject と本文だけで判定してる訳でもなさそうなので、
そうでも無いと思ってますけど。
ちゃんと日本語化するには日本語版 (または CJK) スプリッタを追加して、
トークンを抽出し、その結果の評価をしないといけないのかもしれません。
今は手に余るので、使ってみて気が向けばそのうち試すかもしれません。
# 敵は本能寺?
【注意】TrackBack 送信なさる場合、
あなたの記事中に参照リンク (当ブログの URL 記述) が必要です。
トラックバックスパム防止のため、御了承ください。
SpamBayes 日本語化 by owa
「ベイズ理論を利用したスパムフィルタ」
って、流行ですね。 うちも、spamassassin
使ってますが、ちと遅い。
「軽い」と言う言葉に魅かれてしまう、あたしでございます。
Seedには他にも、「 bsfilter 」 なる物が有りますけど、
これで、三つ巴ですねー。全てベイズ理論。
UnicodeBlockTokenizer
http://tokuhirom.dnsalias.org/~tokuhirom/wiki/UnicodeBlockTokenizer
Unicode の Block によって、トーカナイズしてくれるライブラリ。
スパムフィルタなどで使うと便利かも。
卒研の副産物です……。
http://owa.as.wakwak.ne.jp/zope/coreblog/123
を見てたら思いだしたので、公開してみました。
Outlook2003の環境でSpambayesをビルドするための覚書
Spambayesは結構重宝しているのだけれど、本家版は日本語のトークンに対応していない。ソースコードのspambyes/tokenizer.pyを見ると、引数なしのsplit()でメッセージの本文を処理している。つまりテキストをスペースで区切っているわけで、分かち書きを用いない言語については考慮されていないということだ。幸いにしてowaさんがパッチを作ってくれているので、それをありがたく使わせていただいている。
つい昨日、さる事情からSpambayesを再ビルドした。当方Windowsの環境...
